Generative versus predictive AI explained
In financial analysis, the difference between creating new data and forecasting future events is the difference between imagination and calculation. Generative AI and predictive AI serve distinct roles, and confusing them can lead to flawed strategies in high-stakes environments. Understanding this distinction is essential for building reliable forecasts that rely on accurate, actionable insights.
Generative AI is designed to create new content. Trained on massive datasets containing millions of examples, it can produce text, code, images, or audio that resembles its training material. Think of it as a creative engine. If you ask it to write a market summary or draft a compliance email, it draws from its vast internal library to generate something novel. It excels at synthesis and creation, but it does not inherently understand the probabilistic future.
Predictive AI, by contrast, is a forecasting tool. As IBM notes, it analyzes historical data to identify patterns and predict future outcomes. It doesn't create new content; it calculates probabilities. In finance, this means predicting stock price movements, identifying customer churn, or forecasting supply chain disruptions. It relies on targeted datasets to learn associations between past events and future results, providing the reliable, data-driven forecasts that underpin serious financial decision-making.
This separation matters because financial decisions require certainty based on evidence, not creative interpretation. While generative models can help analysts summarize complex reports quickly, predictive models are the ones that tell you whether a trade is likely to succeed. The focus must remain on the predictive capabilities that turn historical data into forward-looking intelligence, ensuring that every recommendation is backed by statistical rigor rather than linguistic flair.
How predictive models forecast market data
Effective prediction follows a clear sequence: define the constraint, compare realistic options, test the tradeoff, and choose the path with the fewest hidden costs. That order keeps the advice usable instead of decorative.
After each step, pause long enough to check whether the recommendation still fits the reader's actual situation. If it depends on perfect timing, unusual access, or a best-case budget, include a simpler fallback.
The simplest way to use this section is to write down the real constraint first, compare each option against it, and choose the path that still works outside ideal conditions.
Generative vs. Predictive AI in Financial Infrastructure
Choosing between generative and predictive AI requires understanding their distinct operational roles. Predictive AI is the workhorse of financial infrastructure, analyzing historical data to forecast future events like market trends or customer churn. It relies on structured datasets to produce reliable, accurate forecasts that drive proactive planning.
Generative AI, by contrast, creates new content—text, code, or reports—based on vast training datasets. While it excels at synthesizing information and automating documentation, it lacks the deterministic precision required for high-stakes numerical prediction. Distinguishing these capabilities prevents the misuse of creative models for analytical tasks.
Predictive models are essential for tasks requiring numerical precision, such as algorithmic trading or credit scoring. Generative models support these efforts by summarizing complex data or drafting regulatory reports, but they should not be relied upon for the underlying quantitative analysis. Using the right tool for each step ensures both efficiency and accuracy in financial decision-making.
Tools and infrastructure for prediction
Building a reliable prediction model doesn't always require a team of data scientists. The current landscape splits into two distinct paths: low-code platforms for rapid business deployment and enterprise-grade frameworks for complex, custom modeling. Choosing the right infrastructure depends on whether you need to answer questions quickly or build a proprietary engine.
For finance professionals who need insights without writing code, low-code AI builders are the most practical entry point. Microsoft's AI Builder allows users to create prediction models by uploading historical data—such as past sales or churn rates—and letting the platform handle the pattern recognition. As Microsoft Learn explains, these models "learn to associate those patterns with outcomes" to forecast future events. Similarly, tools like Pecan AI focus entirely on the predictive workflow, automating the tedious data preparation steps so business analysts can focus on interpreting the forecast rather than cleaning spreadsheets.
On the other end of the spectrum, enterprise solutions offer the depth required for high-stakes financial modeling. Platforms like IBM Watson allow for more granular control over algorithm selection and feature engineering, which is essential when dealing with noisy market data or complex regulatory constraints. These tools support the full lifecycle of predictive AI, from data ingestion to model deployment, ensuring that predictions are not just accurate but also auditable and explainable.
The choice between these approaches often comes down to speed versus control. Low-code tools get you to a decision faster, while enterprise frameworks provide the robustness needed for long-term strategic planning. Regardless of the tool, the underlying principle remains the same: predictive AI transforms historical data into actionable foresight.

Recommended Learning Resources
To deepen your understanding of how these tools work under the hood, the following resources provide a solid foundation in predictive modeling and financial AI.



As an Amazon Associate, we may earn from qualifying purchases.
Building a reliable prediction strategy
Moving from theory to production requires discipline. Unlike generative models that create new content, predictive AI analyzes historical data to forecast future events with precision. To build a strategy that withstands high-stakes scrutiny, you must treat model validation as a continuous process, not a one-time check.
Garbage in, garbage out. Before training any model, audit your datasets for bias, missing values, and temporal leaks. Microsoft notes that prediction models learn to associate patterns in historical data with outcomes; if the historical data is flawed, the forecast will be too. Clean, structured data is the foundation of any reliable prediction strategy.
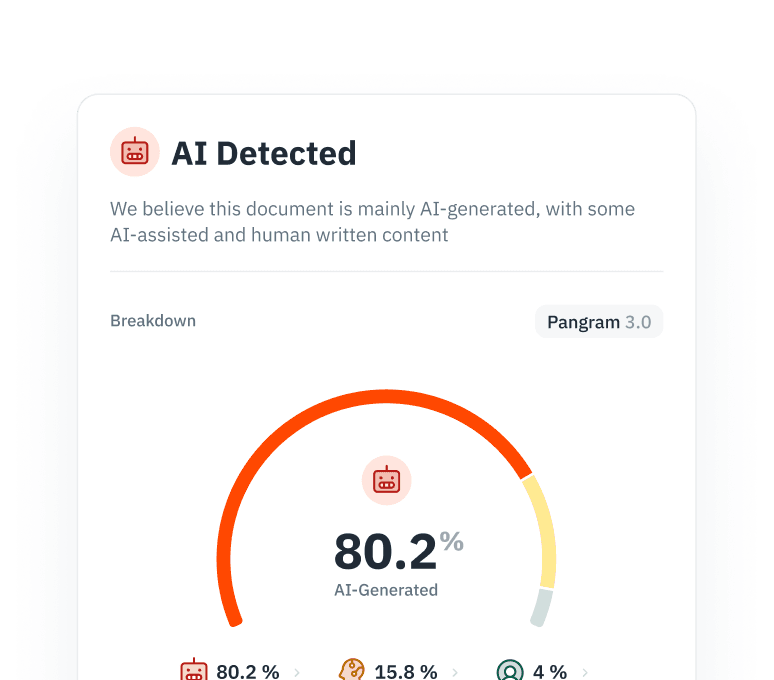
Never trust a model on training data alone. Use out-of-sample testing to simulate how the model would have performed on unseen market data. This step reveals overfitting—where the model memorizes noise instead of learning signal. IBM emphasizes that predictive AI must be tested against real-world variability to ensure it can handle unexpected shifts in market conditions.
Markets change, and so do the patterns your model relies on. Implement MLOps pipelines to monitor for data drift and concept drift in real time. When the statistical properties of the input data shift, the model’s accuracy degrades. Automated alerts allow you to retrain or adjust the model before it causes financial loss.
-
Audit data for bias and completeness
-
Run out-of-sample backtests
-
Set up drift monitoring alerts
-
Define retraining triggers
In high-stakes environments, reliability beats novelty. A simple, well-validated model often outperforms a complex black box that cannot be audited. By focusing on data quality and continuous monitoring, you build a prediction strategy that investors and stakeholders can trust.
Common questions about AI predictions
How does predictive AI differ from generative AI in finance? Predictive AI analyzes historical data to identify patterns and forecast future outcomes, such as stock movements or customer churn. Generative AI creates new content like text or code based on training data. In finance, predictive models provide the probabilistic certainty needed for trading and risk management, while generative models assist with documentation and synthesis.
What data is required for predictive modeling? Predictive models require structured, historical data. This includes past sales figures, customer interaction logs, or market price histories. The quality of this data is critical; biased or incomplete data will result in inaccurate forecasts. Microsoft AI Builder and similar platforms require users to upload clean, labeled datasets to train the model effectively.
Can I use low-code tools for financial prediction? Yes. Platforms like Microsoft AI Builder and Pecan AI allow finance professionals to create prediction models without writing code. These tools automate data preparation and pattern recognition, enabling business analysts to generate forecasts for churn, sales, or risk. However, for highly complex or proprietary models, enterprise-grade frameworks like IBM Watson may offer the necessary control and auditability.
How do I ensure my prediction model remains accurate over time? Markets are dynamic, and patterns shift. You must implement MLOps pipelines to monitor for data drift (changes in input data) and concept drift (changes in the relationship between inputs and outputs). Regular backtesting against new, unseen data helps detect when a model is degrading, triggering retraining before it impacts financial decisions.
No comments yet. Be the first to share your thoughts!