Define your prediction scope
Before writing code or selecting a model, you must determine the nature of the prediction. AI-generated prediction infrastructure splits into two distinct paths: physical asset damage and market data. These paths require completely different data sources, model architectures, and validation methods. Confusing the two leads to infrastructure that fails under real-world conditions.
Physical asset damage
This scope targets tangible infrastructure, such as bridges, pipelines, or building structures. The goal is to predict physical failure modes like moisture damage, structural wear, or corrosion. Models in this category rely on sensor data, satellite imagery, or historical maintenance logs. Research indicates that AI algorithms can accurately predict moisture damage, enabling better material selection and proactive maintenance planning [[src-serp-1]].
Building this infrastructure requires time-series data from IoT sensors or computer vision models trained on visual inspections. The output is usually a probability of failure within a specific timeframe, allowing operators to schedule repairs before catastrophic breakdowns occur.
Market data prediction
This scope focuses on financial or economic indicators, such as stock prices, commodity trends, or currency fluctuations. The data here is abstract, high-frequency, and often noisy. Unlike physical sensors, market data is influenced by human behavior, geopolitical events, and regulatory changes. Predictive AI in this domain turns vast amounts of transactional data into foresight, helping businesses anticipate shifts rather than react to them [[src-serp-4]].
Infrastructure for market prediction typically involves natural language processing for news sentiment analysis combined with quantitative models for price action. The stakes are financial, and the latency requirements are often much stricter than in physical asset monitoring.
Why the distinction matters
Choosing the wrong path early on wastes resources. Physical asset models prioritize spatial accuracy and sensor integration. Market models prioritize latency and sentiment analysis. Defining your scope now ensures you build the correct data pipeline and select the appropriate machine learning framework.
Select the right data sources
Building accurate AI prediction models starts with identifying high-quality, official, or primary data streams. Whether you are training for sensor feeds or financial records, the integrity of your infrastructure depends on the purity of the input. Secondary datasets often carry hidden biases or lagging indicators that degrade model performance over time. Prioritize direct access to raw logs, official government repositories, and verified API endpoints.
Structured vs. Unstructured Data
Choosing between structured and unstructured data sources requires balancing predictability with depth. Structured data offers immediate compatibility with standard algorithms but may miss contextual nuances. Unstructured data, such as maintenance logs or sensor text, provides richer detail but demands significant preprocessing. The table below outlines the trade-offs for prediction accuracy.
| Source Type | Prediction Accuracy | Preprocessing Effort |
|---|---|---|
| Structured (CSV, SQL) | High (consistent patterns) | Low |
| Unstructured (Logs, Text) | Variable (context-dependent) | High (NLP required) |
Official and Primary Sources
For high-stakes infrastructure projects, official sources reduce regulatory risk and improve trust. The Federal Highway Administration (FHWA) provides standardized datasets for transportation networks, which are essential for sustaining economic and societal quality of life. Similarly, academic gap studies from MDPI highlight how AI techniques improve infrastructure performance when fed with verified primary data. Always verify the provenance of any dataset before integrating it into your training pipeline.
-
Confirm data freshness and update frequency
-
Validate source against official government or industry repositories
-
Check for missing values or known biases in historical records
-
Ensure API endpoints have sufficient rate limits for training



As an Amazon Associate, we may earn from qualifying purchases.
Deploy the prediction model
Deployment transforms a trained model from a local experiment into a live service that ingests data and returns forecasts. This phase requires careful coordination between the model artifact, the inference engine, and the surrounding infrastructure. The goal is low-latency serving with high availability, ensuring the ai-generated prediction infrastructure remains reliable under load.
1. Package the model for inference
Export the trained model into a standardized format compatible with your serving framework. Common formats include ONNX, TorchScript, or TensorFlow SavedModel, depending on the underlying library. Include all necessary dependencies, such as tokenizer files for NLP models or feature encoders. This packaging ensures the model runs identically in production as it did during training, preventing "drift" caused by environment differences.
2. Containerize the inference service
Wrap the inference engine and its dependencies in a Docker container. This isolates the service from the host system, making it portable across development, staging, and production environments. Define the container’s resources (CPU, GPU, memory) explicitly to prevent resource contention. A well-defined Dockerfile ensures that every deployment is reproducible and version-controlled.
3. Configure the serving endpoint
Expose the container via a REST API or gRPC endpoint. Use a framework like FastAPI, TorchServe, or TensorFlow Serving to handle incoming prediction requests. Implement health checks to monitor the service’s status and auto-scaling rules to handle traffic spikes. For high-stakes financial predictions, consider implementing request batching to optimize GPU utilization without sacrificing latency.
4. Validate with shadow traffic
Before routing live traffic, deploy the new model alongside the current version in "shadow mode." Route a copy of incoming requests to the new model without returning its predictions to the user. Compare the new model’s outputs against the production model’s results and ground-truth labels. This step catches regressions early, ensuring the new ai-generated prediction infrastructure performs as expected before full rollout.
5. Roll out and monitor
Once validation passes, switch traffic to the new model using a canary or blue-green deployment strategy. Monitor key metrics: inference latency, error rates, and prediction drift. Set up alerts for anomalies, such as a sudden drop in prediction confidence or a spike in response times. Continuous monitoring ensures the infrastructure adapts to changing data patterns without manual intervention.
Verify model accuracy
Before deploying AI-generated predictions for infrastructure, you must establish rigorous validation protocols. Relying on unverified models risks costly failures, such as misjudging moisture damage or structural stress. Validation is not a single test but a continuous process of comparing model outputs against real-world data.
Start by splitting your historical data into training and testing sets. This prevents the model from memorizing past events rather than learning underlying patterns. Use metrics like mean absolute error (MAE) or root mean square error (RMSE) to quantify prediction偏差. For infrastructure damage, researchers have found that AI algorithms can accurately predict moisture damage when properly validated, enabling better material selection and maintenance planning [src-serp-1].
Next, perform a sensitivity analysis. Identify which variables most influence the model’s predictions. If minor fluctuations in sensor data cause wild swings in output, the model is unstable. Review literature on AI implementation in infrastructure projects to identify common gaps in performance and efficiency [src-serp-5]. Address these gaps by refining your feature engineering or adjusting model hyperparameters.
Finally, conduct a pilot run in a controlled environment. Monitor the model’s predictions against actual outcomes over a set period. Document any discrepancies and iterate. Only after this phase should you consider full-scale adoption.
-
Split data into training and testing sets
-
Calculate MAE or RMSE metrics
-
Perform sensitivity analysis on key variables
-
Conduct a controlled pilot run
-
Document discrepancies and iterate
Common prediction errors
Even with robust ai-generated prediction infrastructure, models can fail when the underlying data shifts. The most frequent pitfall is overfitting, where a system memorizes historical noise rather than learning generalizable patterns. This leads to high accuracy on backtests but poor performance in live markets. To correct this, apply regularization techniques and validate models against unseen data segments that reflect real-world volatility.
Data drift is another critical failure point. As market conditions evolve, the statistical properties of the input data change, causing the model’s predictions to become stale. For example, a model trained on pre-2020 trading volumes may struggle with current liquidity patterns. Regularly retrain your infrastructure using recent data windows to maintain relevance.
Finally, avoid ignoring structural breaks. Black swan events or regulatory changes can render historical correlations invalid. Incorporate stress-testing scenarios into your infrastructure to ensure predictions remain grounded even when the market landscape shifts dramatically.
Frequently asked: what to check next
Building AI-generated prediction infrastructure involves complex technical and strategic decisions. Below are answers to common questions about deployment, security, and market viability.
Work through AI-Generated Prediction Infrastructure


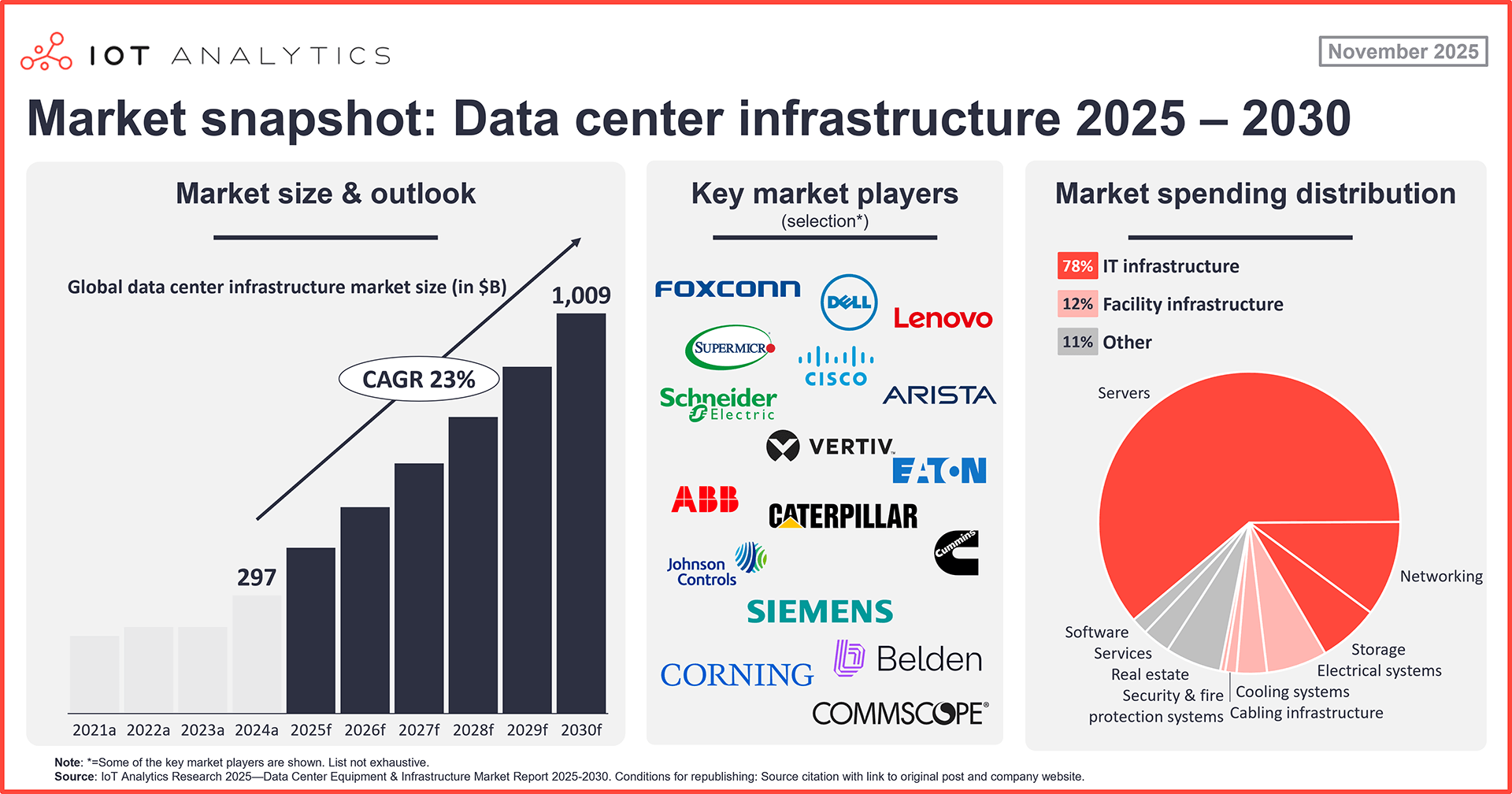
No comments yet. Be the first to share your thoughts!