Set up your prediction data source
Building an AI-Generated Prediction model for onchain metrics starts with data quality. Predictive AI uses statistical analysis and machine learning to identify patterns and forecast events. If your data is noisy or unverified, your model will learn the noise. This leads to garbage-in, garbage-out predictions.

Select a source that provides raw, unaggregated onchain data. Avoid third-party aggregators that may smooth out volatility or introduce latency. Official providers like Dune Analytics or The Graph offer direct access to blockchain state. This ensures your AI-Generated Prediction model trains on the actual truth of the ledger, not a sanitized version.
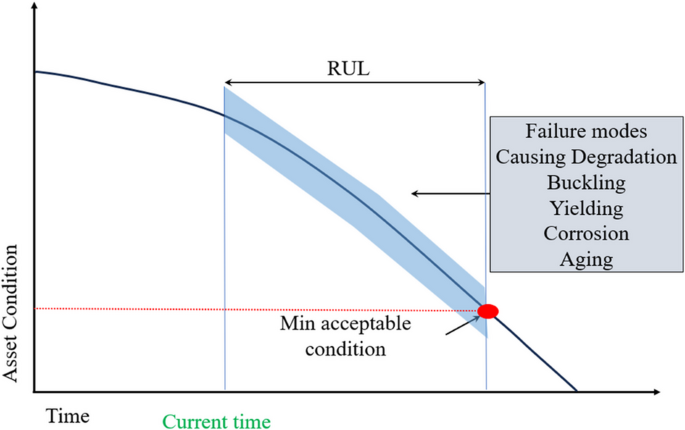
Determine the lookback period for your training data. For onchain metrics, shorter timeframes often capture more relevant volatility patterns than years of stagnant data. Align your window with the specific prediction horizon. If you are predicting short-term price movements, focus on recent blocks. If you are modeling long-term adoption, include broader historical cycles.
Remove outliers caused by known events like exchange hacks or major protocol upgrades that don't reflect normal market behavior. Label your data points clearly. For example, tag blocks where major governance votes occurred. This helps the AI distinguish between structural shifts and random noise. Clean data is the foundation of any reliable AI-Generated Prediction system.
Train the model with historical outcomes
Training an AI-Generated Prediction model is where theoretical assumptions meet actual market data. You are not just feeding numbers into a black box; you are teaching the algorithm to recognize the subtle correlations that drive onchain behavior. Without rigorous training on historical outcomes, any forecast is merely a guess.
The process requires discipline. As Microsoft Learn outlines, creating a prediction model involves a structured sequence of data preparation, feature engineering, and validation. Skipping steps here compromises the entire forecasting architecture.
Start by ingesting raw onchain data—transaction volumes, gas fees, active addresses, and token flows. Remove outliers and handle missing values. Predictive AI relies on consistent patterns; noisy data introduces false signals that degrade forecast accuracy.
Identify which historical variables actually correlate with future price or volume movements. Not every metric is useful. Use statistical tests to filter for features that have a proven track record of influencing the target variable, reducing the risk of overfitting.
Feed the cleaned, feature-selected data into your chosen algorithm. Whether using regression, time-series analysis, or machine learning classifiers, the model iterates through the data to minimize error. This is where the AI-Generated Prediction framework learns the underlying structure of the market.
Test the model against a holdout dataset it has never seen. This confirms that the model can generalize to new market conditions rather than just memorizing past events. A high accuracy score on training data but poor validation results indicates overfitting.
This training phase is foundational. A well-trained model provides the baseline for all subsequent forecasting. If the historical patterns are misinterpreted here, no amount of post-processing will fix the output.
Validate accuracy against live markets
You have built an AI-Generated Prediction model, but backtesting is a rear-view mirror. It shows you what happened, not what will happen. To ensure your onchain forecasting isn't overfitting to historical noise, you must stress-test it against live market conditions. This phase separates theoretical code from functional financial tools.
Start by running a "paper trading" mode where your model executes predictions without moving capital. Compare the model's output against real-time oracle data and onchain metrics. If the model predicts a price movement, check if the actual market data aligns within a reasonable margin of error. This immediate feedback loop reveals latency issues or logic flaws that static datasets hide.
| Metric | Backtesting (Historical) | Forward Testing (Live) |
|---|---|---|
| Data Environment | Static, clean historical records | Dynamic, noisy real-time feeds |
| Overfitting Risk | High (curve-fitting to past) | Low (tests generalization) |
| Latency Impact | Ignored | Critical (execution speed) |
| Market Impact | None | Real slippage and fees |
IBM notes that predictive AI uses machine learning to forecast future events by identifying patterns in data. However, those patterns shift as market participants adapt. Your validation process must account for this volatility. Use a small allocation of capital to test your predictions in the wild. Track the deviation between predicted and actual outcomes daily.
If your model fails in live conditions, do not discard it entirely. Analyze the specific market conditions where it struggled. Was it high volatility? Low liquidity? Adjust your training data to include these edge cases. This iterative process ensures your AI-Generated Prediction guide remains robust as the onchain landscape evolves.
Deploy tools for automated forecasting
Building an onchain forecasting model is only half the battle; the other half is keeping it running without you staring at a screen all day. To make daily trading decisions, you need to move from manual analysis to an automated pipeline that ingests data, runs predictions, and alerts you to opportunities.
Predictive AI is widely used to gain insights into customer behavior and optimize decision-making across industries, but in crypto, the stakes are higher and the data moves faster. You need tools that can handle volatility and provide reliable, accurate forecasts rather than static reports.
Step 1: Select your prediction engine
Start by choosing a platform that specializes in predictive analytics. Tools like Pecan AI allow you to build models without deep coding expertise, focusing on the "10-20-70 rule" where most effort goes into people and processes rather than just algorithms. For more custom needs, libraries like TensorFlow or PyTorch offer granular control over your neural networks.
Step 2: Automate data ingestion
Your model is only as good as its input. Set up automated pipelines to pull onchain data—such as whale movements, liquidity pool changes, and transaction volumes—into your prediction environment. Ensure your data source is reliable and updates in real-time to avoid lagging indicators that miss market shifts.
Step 3: Configure alert thresholds
Don't just run predictions; act on them. Configure your system to send alerts when the AI's confidence level exceeds a certain threshold or when predicted price movements deviate significantly from current trends. This turns passive data into actionable trading signals.
Recommended Hardware and Software
Running these models locally or in the cloud requires specific setups to ensure speed and reliability.


As an Amazon Associate, we may earn from qualifying purchases.
Avoid common prediction pitfalls
Building an onchain forecasting model is less about coding and more about debugging your assumptions. The difference between a profitable strategy and a blown account often comes down to avoiding three specific traps: overfitting, ignoring black swan events, and relying on single-source data.
Don’t overfit your historical data
Overfitting happens when your model memorizes past noise instead of learning actual market signals. It performs beautifully on backtests but fails immediately in live trading. To fix this, use out-of-sample testing. Hold back 20% of your historical data and never let the model see it during training. If the model can’t predict unseen data, it’s not ready for the mainnet.
Account for black swan events
Onchain markets are prone to sudden, extreme volatility—flash crashes, protocol exploits, or regulatory announcements. Standard models assume normal distribution, which is a dangerous lie in crypto. You must stress-test your AI-generated prediction guide against historical crises like the 2022 Terra collapse or the FTX bankruptcy. If your model doesn’t survive those scenarios, it’s too fragile for real-world use.
Diversify your data sources
Relying on a single data provider creates blind spots. If that provider’s node lags or filters out certain transactions, your model acts on stale or incomplete information. Combine onchain metrics (like TVL or gas fees) with offchain sentiment data and order book depth. This triangulation ensures your forecasting model remains robust even if one data stream fails.
Ai-generated prediction guide: frequently asked: what to check next
Predictive AI uses historical data to forecast future events, distinct from generative models that create new content. Understanding its capabilities helps you build reliable onchain forecasting models.
No comments yet. Be the first to share your thoughts!